


Parts 1 and 2 of our technology walkthrough reached a point where transcription was completed and the speakers within the call were identified. The results from these aspects of the voice analytics solution can be seen below:

Figure 1: Transcription and Speaker Identification
This is all basic voice analytics functionality. But for the solution to truly deliver value, it should allow you to analyze the transcribed text and automatically extract key features and insights that can be very helpful for the business. As part of this process, the following components are involved:

Figure 2: Text Analytics Flow
Let’s look at the components in more detail using the same audio clip, between Omarosa and President Trump. To listen to the clip, please click on the link below.

Key Phrase / Entity extraction and Named Entity Recognition
Key-Phrases provide a concise description of the content of a conversation and are useful for clustering important topics, further helping to connect different conversations together. Named Entity Recognition, on the other hand, extracts and classifies key-phrases into high level, pre-defined categories.
In Just Listen, both these use a combination of custom models, natural language processing and the Microsoft text analytics service. The below code snippet performs the above spoken of functions. Want to see how it works? Here's a Free Trial link.
# Calling the Entity Extraction Service
response = requests.get(https://southeastasia.api.cognitive.microsoft.com/luis/v2.0/apps/40fac932-f329-405a-96ff-fe9d58d4355f?, text)
entity_json = response.json()
# Storing the obtained entities
entity_json = {
"entity" : entity_json['entity'],
}
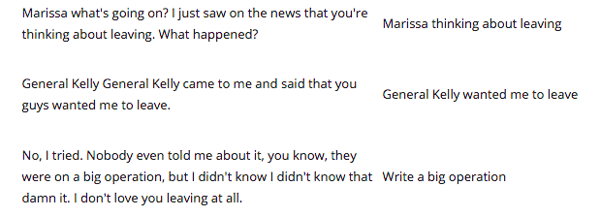
Figure 4 at the bottom shows the output after the code is applied.
Summarization
Auto-summarization is the process of shortening a piece of text, to create a more targeted summary of the content with the major points to enhance user readability.
The code below uses an open source summarization package which consists of neural network models combined with natural language pre-processing:
from sumy.parsers.plaintext import PlaintextParser
def docsummarizer(fileInfo):
# Running the summarizer
parser = PlaintextParser.from_string(allText, Tokenizer(LANGUAGE))
stemmer = Stemmer(LANGUAGE)
summarizer = Summarizer(stemmer)
summarizer.stop_words = get_stop_words(LANGUAGE)
for sentence in summarizer(parser.document, SENTENCES_COUNT):
allSummary = allSummary + str(sentence)
Figure 3 below shows the output obtained when the call text is run through the above code.
It is useful for long pieces of text, where we can easily extract the summary for further processing and better understanding.
Tone Analysis
Tone Analysis is used to analyze emotions and tones in what the speakers say to each other over the call. In a contact center scenario, it is used to monitor customer service and support conversations so that agents can respond to customers appropriately. The service behind this is the Watson Tone Analyzer and it uses linguistic analysis to detect joy, fear, sadness, anger, analytical, confident and tentative tones found in text. Businesses can use the service to learn the tone of their speakers’ communications and to derive insights or respond appropriately, or in a contact center scenario, to understand and improve customer conversations in general.
The following code sets up, passes the text, calls the tone analyzer service and receives the response which is a collection of various tones and their values. It works by analyzing the different words and context of the text to derive these results.
# Setting up the ToneAnalyzer
tone_analyzer = ToneAnalyzerV3(username = toneanalyzer_user, password = toneanalyzer_pass, version = toneanalyzer_ver)
opToneAnalysis = tone_analyzer.tone(tone_input=Text, content_type="text/plain")
When we pass the text through this service we obtain the results as seen in Figure 4 below.
Sentiment Analysis
It is the process of computationally identifying and categorizing opinions expressed in a piece of text to determine whether the speakers’ attitude towards a topic or product is positive, negative, or neutral. In our solution, the Microsoft Text Analysis service is used to extract the sentiment of the speakers. It uses the scores of different words and the context to come up with a relevant score using machine learning and natural language processing models.
# Calling the Sentiment Service
sent_req = urllib.request.Request(“https://southeastasia.api.cognitive.microsoft.com/text/analytics/v2.0/sentiment”, data, headers)
sent_resp = urllib.request.urlopen(request2)
sent_resp_json = json.loads(response2.read().decode('utf-8'))
sentiment = response2json['documents'][0]['score'] # Getting the sentiment score
When we run our text through this code, the output indicates either the positive or negative sentiment level associated with each spoken sentence.
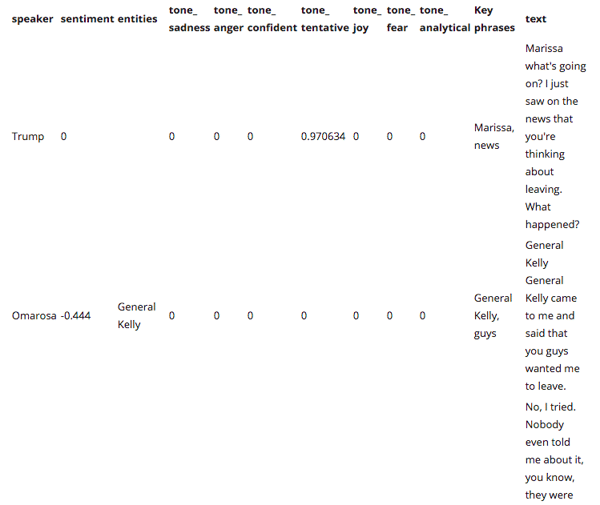
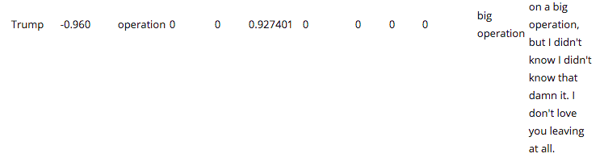 Figure 4: Entities, Key Phrases, Tone Analysis and Sentiments
Figure 4: Entities, Key Phrases, Tone Analysis and Sentiments

.svg)

.svg)