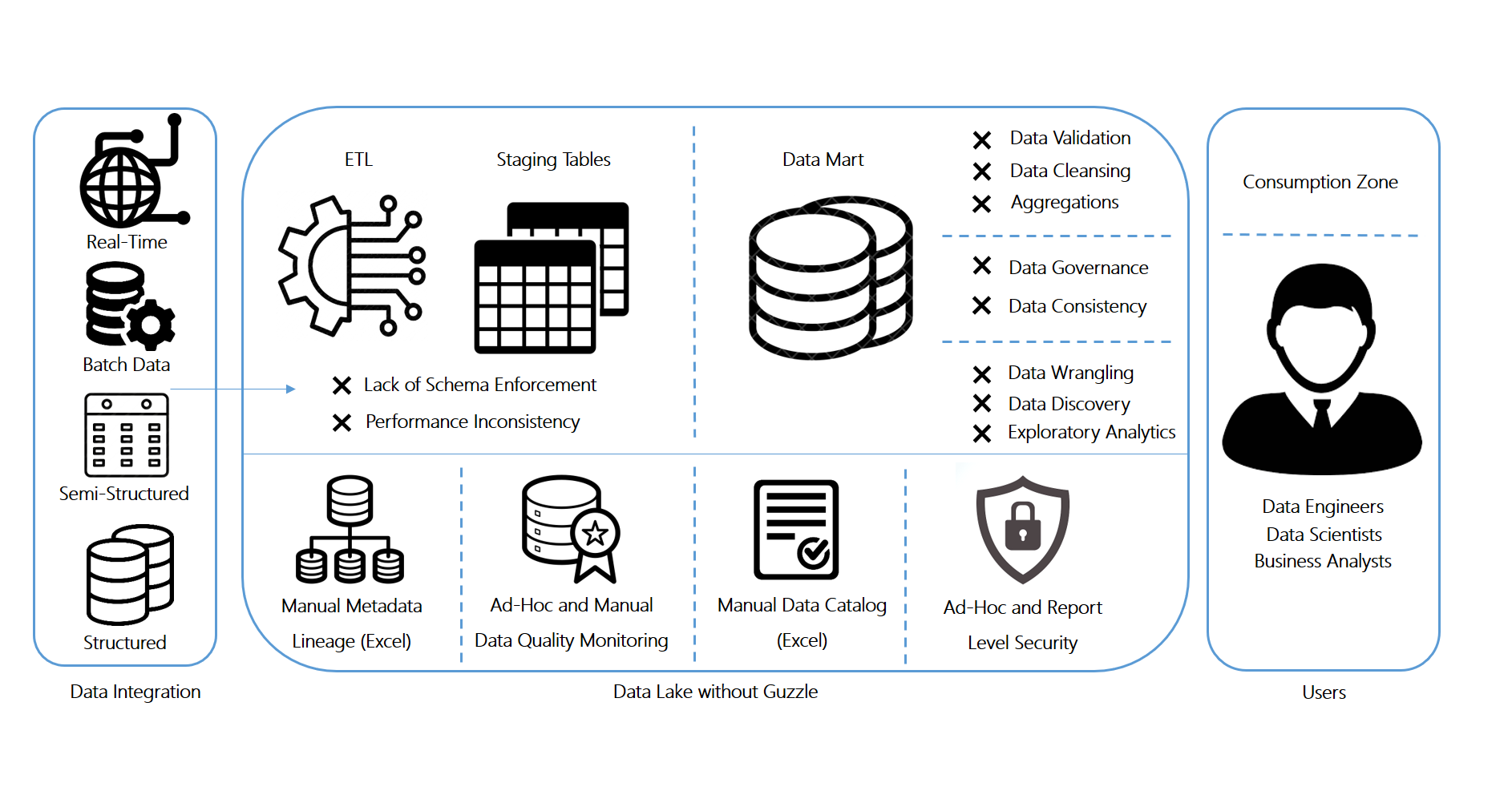
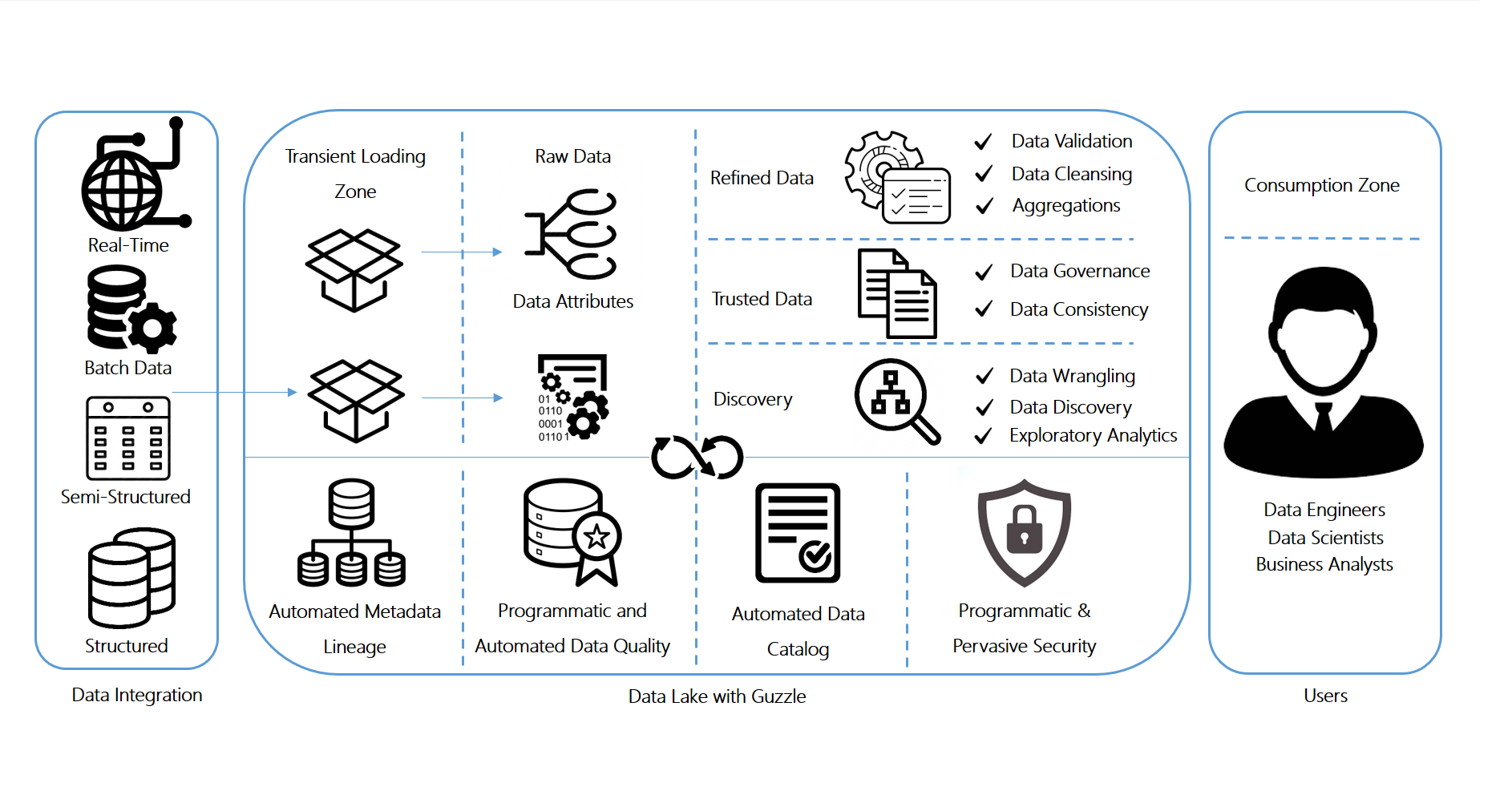
Guzzle: Workbench for Data Engineering & Science
GUZZLE – is a Spark Native workbench for data scientists and data engineers to productionize their data pipelines at scale. Released under the Apache 2.0 license, Guzzle can natively handle diverse workloads (batch, streaming, real-time and API) and uses a declarative framework and UI to build production quality pipelines with agile timelines. Native DevOps integration, with audit and governance controls bolsters rapid development sprints to fast-tracked delivery cycles, with the quality controls of a production deployment.

















.svg)

.svg)